")
")

 Autor: Jacek Grymuza
Autor: Jacek Grymuza
SIEM jest centralnym systemem bezpieczeństwa dla większości organizacji…
Głównym systemem analitycznym do wykrywania i analizy zagrożeń bezpieczeństwa w organizacji jest system klasy SIEM. W systemie tym korelowane są logi z wielu źródeł danych, takich jak systemy operacyjne, bazy danych, urządzenia sieciowe, aplikacje czy też systemy bezpieczeństwa, w celu wykrywania potencjalnych zagrożeń i nadużyć bezpieczeństwa. Widoczność zagrożeń w tym systemie uzależniona jest nie tylko od jakości logów monitorowanych źródeł danych, ale i od zaimplementowanych korelacji. Korelacja to nic innego jak sekwencja określonych zdarzeń, które wskazują na wystąpienie określonej nieprawidłowości bezpieczeństwa. Kolekcjonując więc wiele źródeł danych w jednym miejscu, nie można zapominać o projektowaniu korelacji międzysystemowych, a więc korelacjach pomiędzy logami pochodzącymi z różnych systemów, których łączy jedna lub więcej wspólnych cech, np. adres IP.
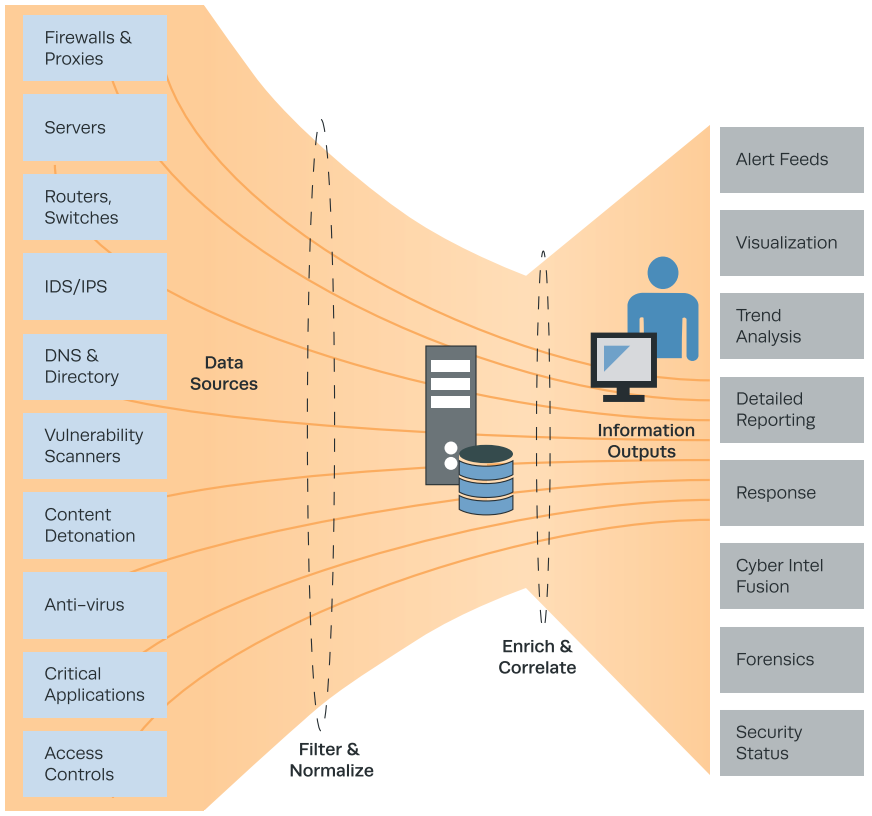
Rysunek 1: Mechanizm działania SIEM1
Monitorowanie flowów sieciowych jest ważnym punktem w projektowaniu defensywy organizacji…
Z jednym istotnych źródeł danych nie tylko dla zespołów NOC/SOC są systemy klasy Network Visibility, do której należy m.in. system FlowControl. Główną zaletą tego systemu jest poprawa widoczności anomalii sieciowych i zagrożeń bezpieczeństwa z poziomu całej organizacji, z racji tego, że monitorowane są flowy sieciowe z wszystkich istotnych urządzeń sieciowych organizacji, a więc widać wszystkie komunikacje sieciowe. Tylko na podstawie samych flowów sieciowych wg framework’u MITRE ATT&CK, o którym pisaliśmy w tym artykule można wykryć ponad 30 technik stosowanych przez cyberprzestępców. Na podstawie kategoryzacji MITRE, w systemie FlowControl zostały stworzone mechanizmy detekcji zagrożeń bezpieczeństwa wykrywające na chwilę obecną zagrożenia z siedmiu taktyk MITRE.
| Taktyka ATT&CK MITRE | Przykłady wykrywanych zagrożeń przez FlowControl XNS |
| Initial Access | Wykrywanie niedozwolonych aktywności sieci P2P |
| Credential Access | Wykrywanie ataków typu brute force na różne usługi, np. HTTP(s), FTP, IMAP, SSH, RDP, LDAPS, MS SQL |
| Wykrywanie nieautoryzowanych komunikacji LLMNR/NetBIOS | |
| Discovery | Wykrywanie anomalii sieciowych mogących mieć związek z bezpieczeństwem |
| Wykrywanie nieautoryzowanego dostępu do określonych usług, np. Internet, DHCP, DNS, Mail Server | |
| Wykrywanie skanowania sieci | |
| Wykrywanie skanowania portów | |
| Wykrywanie rozprzestrzeniania się złośliwego oprogramowania | |
| Lateral Movement | Wykrywanie nieautoryzowanych połączeń RDP |
| Command and Control | Wykrywanie aktywności na podejrzanych portach (w oparciu o Black i White-listy) |
| Wykrywanie nieszyfrowanych połączeń do krytycznych serwerów/usług | |
| Wykrywanie komunikacji z podejrzanymi adresami IP, np. Botnet, Malware, C2, Ransomware | |
| Wykrywanie naruszeń polityk bezpieczeństwa, np. TOR, Open DNS, Open Proxy | |
| Exfiltration | Wykrywanie anomalii dot. protokołu DNS, np. Abnormal DNS Query Limit, Abnormal DNS Response Limit, DNS Transfer Limit |
| Wykrywanie dużej liczby niechcianych maili (SPAM) | |
| Wykrywanie prób eksfiltracji danych | |
| Wykrywanie transferów ogromnej ilości danych w krótkim przedziale czasu do/z organizacji | |
| Wykrywanie anomalii w protokołach sieciowych | |
| Impact | Wykrywanie ataków DoS, np. ICMP Flood, TCP Flood, UDP Flood |
| Wykrywanie ataków amplifikacyjnych DDoS, np. DNS Amplification |
Korelacje międzysystemowe...
W związku z tym, że systemy klasy Network Visibility analizują ruch pochodzący z flowów sieciowych, pojedyncze alarmy z takiego systemu mogą nie być wystarczająco precyzyjne, aby zespół bezpieczeństwa podejmował się obsługi każdego pojedynczego alertu. Oprócz tego, tak jak w każdym systemie do wykrywania anomalii, niepoprawnie stuningowane reguły bezpieczeństwa mogą generować zbyt wiele False Positives, co de facto po pewnym czasie może prowadzić do ignorowania alertów z takich systemów przez zespół SOC. Z kolei „przekręcenie śrubki” w drugą stronę, gdzie systemy bezpieczeństwa wykrywają tylko oczywiste przypadki, może doprowadzić do tego, że zostaną przeoczone prawdziwe alarmy. Jaki jest więc złoty środek?
Jednym z rozwiązań tego problemu może być projektowania w SIEM korelacji międzysystemowych, które będą zwiększały krytyczność, a tam samym priorytety obsługi potencjalnych incydentów bezpieczeństwa. A zatem krytyczność pojedynczego alertu z systemu FlowControl powinna być inna niż cross-korelacja tego alertu z alertami wygenerowanymi przez inne systemy w kontekście określonego atrybutu. Na przykład pojedyńczy alert o nazwie „Brute Force Attack:WS-Management and PowerShell remoting via HTTP” powinien mieć inny priorytet obsługi niż ten sam alert powiązany dodatkowo z sekwencją zdarzeń podejrzanych aktywności wykrytych za pomocą monitorowania Sysmon. Występowanie wielu niepożądanych aktywności w określonym przedziale czasu, często świadczy o tym, że atakujący potrącił kilka „pachołków”, które rozstawiliśmy w różnych miejscach naszej organizacji aby wykrywać niepożądane aktywności, aby zwiększyć prawdopodobieństwo wykrycia rzeczywistego naruszenia procedur bezpieczeństwa organizacji. Tymi pachołkami są dla nas mechanizmy detekcji zagrożeń, które powinny być połączone z procedurami obsługi incydentów bezpieczeństwa.
Przykładowe korelacje międzysystemowe
| Use Case | FlowControl | QRadar | Wartość dodana korelacji międzysystemowych |
| Wykrycie podejrzanej aktywności WinRM | • Wykrycie aktywności na podejrzanym porcie (5985) w danym segmencie sieci • Wykrycie ataku brute force na porcie 5985 • Wykrycie anomalii sieciowych | Na podstawie logów Sysmon: • Wykrycie uruchomiania podejrzanych aplikacji (Systools) • Wykrycie uruchamiania aplikacji z katalogów tymczasowych | • Szybsze wykrycie prawdziwych incydentów bezpieczeństwa • Możliwość nadania wyższego priorytetu korelacjom międzysystemowym • Możliwość wykrycia ataku w czasie jego trwania • Ograniczenie liczby False Positives |
| Wykrycie ataku DDoS na sewerze webowym | • Wykrycie ataku DDoS na podstawie mechanizmów detekcji systemu FlowControl | Na podstawie logów Apache: • Wykrycie ataku na podstawie ogromnej liczby kodów odpowiedzi 4xx w krótkim przedziale czasu | |
| Wykrycie anomalii w protokole DNS | • Wykrycie anomalii w protokole DNS • Wykrywanie nieautoryzowanych serwerów DNS • Wykrywanie tzw. Open DNS | Na podstawie logów DNS: • Wykrycie długich żądań DNS • Wykrycie wielu żądań TXT z tego samego adresu IP • Wykrycie wielu żądań NXDOMAIN |
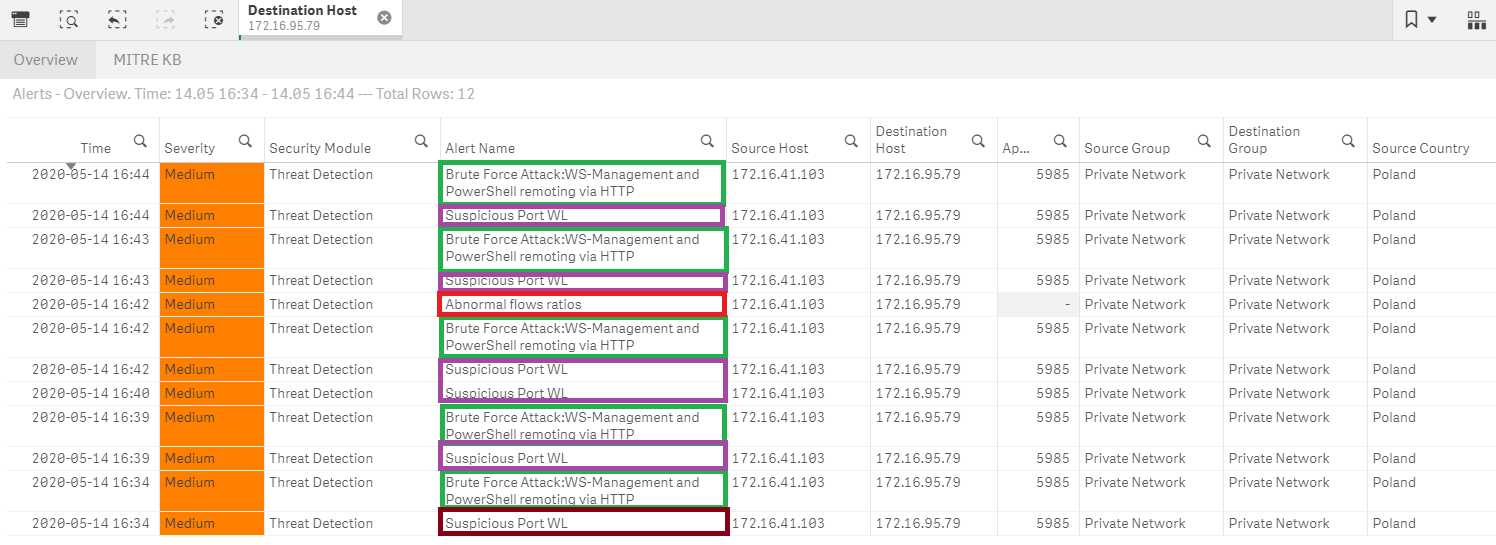
Rysunek 2: Wykrycie podejrzanych aktywności dotyczących usługi WinRM w systemie FlowControl

Rysunek 3: Korelacje alertów FlowControl z logami SysMon
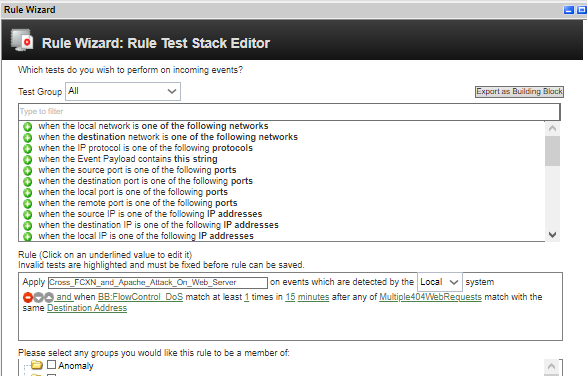
Rysunek 4: Przykład reguły międzysystemowej w systemie QRadar SIEM
Podsumowanie
Korelacje międzysystemowe zwiększają skuteczność wykrywania zagrożeń poprzez generowanie mniejszej liczby False Positives. Systemy klasy Network Visibility są cennym źródeł informacji dla analityków zajmujących się obsługą incydentów bezpieczeństwa, czy też Threat Huntingiem, a także dla systemów klasy SIEM, które korelują logi z różnych systemów. Aby wysłać alerty bezpieczeństwa z systemu FlowControl do SIEM wystarczy podać w konfiguracji adres IP oraz port serwera Syslog. Oczywiście, nic nie stoi na przeszkodzie, ażeby analiza flowów sieciowych odbywała się bezpośrednio na silniku analitycznym systemu SIEM. W takim przypadku musimy rozważyć dodatkowe aspekty dotyczące rozbudowy architektury SIEM umożliwiającej przeanalizowanie miliardów flowów sieciowych dziennie, koszty dodatkowej licencji oraz koszty zasobów potrzebnych do zaprojektowania logiki wykrywającej anomalie i zagrożenia bezpieczeństwa w oparciu o flowy. Bez względu na to, którą drogę wybierzemy, starajmy się projektować reguły bezpieczeństwa w oparciu o możliwie jak największą liczbę źródeł danych, aby liczba pułapek pozostawionych dla atakujących była jak największa i spójna z procesem obsługi incydentów bezpieczeństwa organizacji. Pamiętajmy również o tym, że bezpieczeństwo jest procesem ciągłym, więc nie ma skończonej liczby scenariuszy bezpieczeństwa, które można zaimplementować w poszczególnych systemach security, aby następnie były one korelowane z alertami pochodzącymi z innych systemów w SIEM.
Autor: Jacek Grymuza, Senior Security Engineer w Passus S.A, członek Zarządu (ISC)2 Poland Chapter